Azure Synapse SQL Pool은 MS-SQL과 비슷한 부분이 많으면서도 다른 부분이 꽤 존재한다.
그 중 하나가 기본키(PRIMARY KEY) 이다. 이에 대해 알아본 내용을 기술해 봅니다.
1. Azure Synapse SQL Pool에서는 PK를 설정할 경우 NONCLUSTERED와 NOT ENFORCED를 모두 사용하는 경우에만 지원됩니다.
: 일반적인 방식으로 PK KEY를 생성 할 수 없습니다.
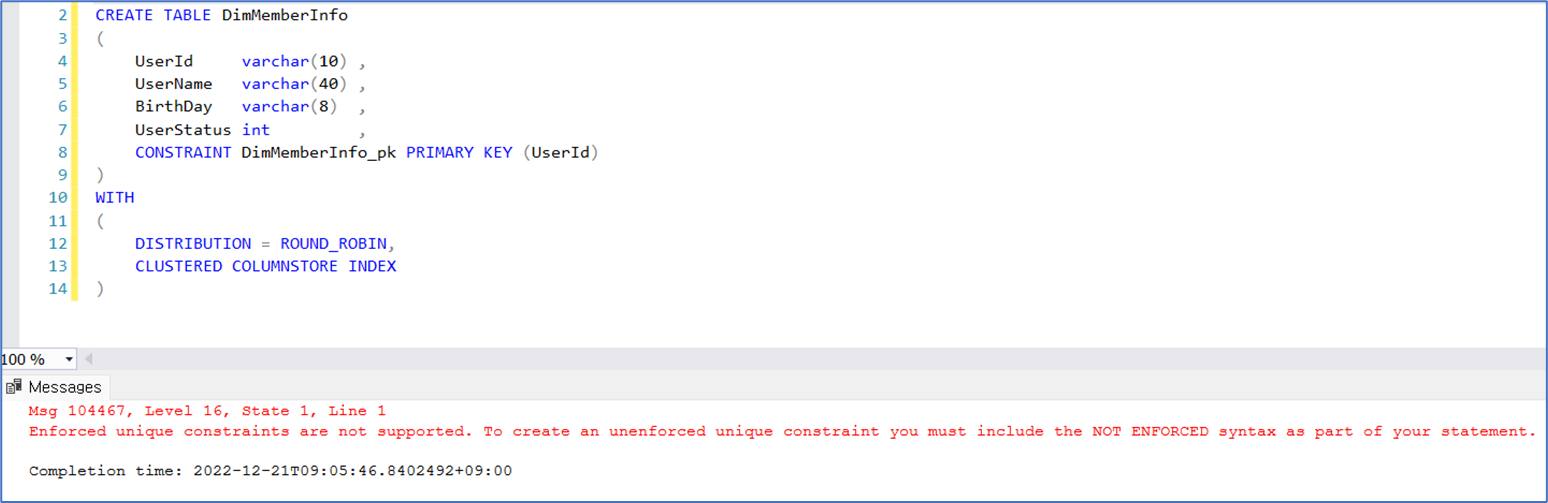
: 아래 예시처럼 NONCLUSTERED와 NOT ENFORCED를 모두 사용해야 생성이 가능합니다.

2. 기본키(PK)이지만 우리가 알던 기본키와는 다르다.!?
무슨 말이지? 할 수 있다. 나 또한 적지 않게 당황한 부분이었다.
: 위에서 만든 테이블에 데이터를 INSERT 해보았습니다.
# 아래 예시에서 보면 우리는 분명 PK를 생성하였는데 PK KEY(UserId)에 동일한 값이 들어갔습니다.!

※ 보통 대부분 DB의 경우 PK KEY는 무결성 제약조건에 의해 중복데이터가 허용되지 않습니다.
그런데 Azure Synapse SQL Pool에서는 중복데이터가 허용된다는 사실입니다.
이해는 안됐지만, 왜 이런 구조인지는 추후에 알아보도록 하겠으며, 이게 끝이 아님.!
또 하나의 다른점이 존재했습니다!

PK Key(UserID) 의 경우 Group by 처리가 되지 않습니다. (참고-Distinct 문도 동일.)
PK Key가 아닌경우는 정상적으로 Group by됨.
이 부분이 두번째로 다른 부분 이었습니다. 자칫 이런 부분을 인지 못한다면, 데이터 검증과정에서
중복된 데이터가 존재 함에도 모르고 지나칠 수 있습니다.
그럼 중복관리는 어떻게??? MS 문서에서는 아래와 같이 쓰라고 권장하고 있습니다.

실제로 프로젝트 수행시에는 UPDATE, INSERT 작업을 할 때 PK키 데이터가 기존 테이블 사용되는지
Not Exists 구문등을 이용해 예외 처리를 하였습니다.
그럼 도대체!!!! Synapse SQL Pool 에서는 PK를 왜 쓰는거야?! 이럴바에는 안쓰고 말지 라는 의문이 들었습니다.
MS 문서에 아래와 같이 기술이 되어 있습니다.
기본 키 및/또는 고유 키를 사용하면 전용 SQL 풀 엔진에서 쿼리에 대해 최적의 실행 계획을 생성할 수 있습니다.
기본 키 열 또는 고유 제약 조건 열의 모든 값은 고유해야 합니다.
눈여겨 보지 않아서 그냥 쓱 넘겼던 부분인데.... 결국 Syanpse SQL Pool에서의 PK란 최적의 실행계획(Plan)을
잡기위해 설정하면 성능 향상을 기대 할 수 있으니... 그런 용도로 쓰란 말이었습니다.
단! 중복키 이런건 사용자가 알아서 잘 관리해야된다는......
이렇게 다양한 테스트를 통해 Synaspe SQL Pool - PK에 대해 확실히 개념을 정립 할 수 있었습니다.
추가로 관련 MS 문서 링크는 아래 달아놨으니... 참고 하시기 바랍니다. ^^
#참고 : 기본, 외래 및 고유 키 - Azure Synapse Analytics | Microsoft Learn